Flows#
Here are some flows of components of MultiRunnable to describe the working details like how it work and what it happen.
Basically, it has 5 sections:
- Work Flow
- Runnable Object - Executor
A executor be initialed to the end.
- Runnable Object - Pool
A pool of executors be initialed to the end.
- Synchronization
Demonstrate how a synchronization feature works with modules Adapter and API.
- Persistence
There are different strategies for File or Database of MultiRunnable. Each of their work flows are slightly different.
- File
About saving as file, it has 3 saving strategies currently:
One Thread One File
All Threads One File
One Thread One File and Compress All
- Database
Connection strategy of Database section
One Single Connection
Connection Pool
- Retry Mechanism
Working flow about retry processing.
Work Flow#
Executor#
Executor like a bridge in MultiRunnable, developers doesn’t need to care about which running strategy object them uses, they just set the argument mode first and use the APIs it provides.
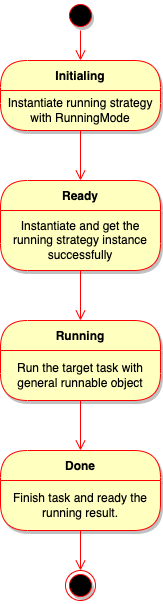
Therefore, the running procedure of Executor as below:
It would initial running strategy object first with the value of option mode.
Instantiate and ready the running strategy instance to use.
Let outside to use the APIs.
Run and done the target tasks. (including initial runnable object, activate them, etc)
Here’s the activity diagram of Executor:
Pool#
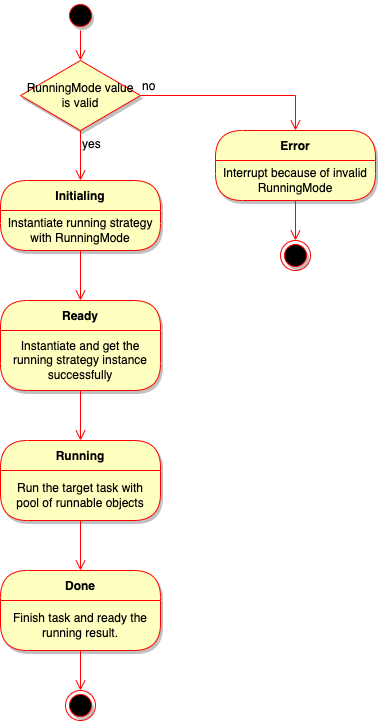
For Pool, it’s mostly same as Executor. The different is:
It would check the value of option mode because it doesn’t support running mode Asynchronous.
Here’s the activity diagram of Pool:
Synchronization#
The synchronization features of MultiRunnable has 2 sections: generating instance (Adapter modules) and operators of instance (API modules). Adapter modules responses of generating feature instance and API modules provides the operators of instance which be initial by Adapter modules.
Therefore, the running procedure of Executor as below:
- Adapter: Generating instance
Set the FeatureMode by property feature_mode.
Instantiate and ready the feature instance by method get_instance.
Assign the instance to the mapping global variable by method globalize_instance.
- API: Provides the APIs (operators) of the instance
Get the instance by protected method _get_feature_instance.
Provides the APIs to outside.
Here’s the sequence diagram of Synchronization:

The synchronization feature classes is the subclass of FeatureAdapterFactory like Lock, Semaphore, etc. About Running Strategy Feature, it’s different feature module with different FeatureMode. For example, it’s multirunnable.parallel.feature module if FeatureMode is Parallel. The global variable is the mapping of each synchronization feature classes.
About details of APIs, please refer to Synchronization API. About software architecture of synchronization features, please refer to Software Architecture of Synchronization.
Persistence#
It has 2 way about persistence of MultiRunnable: as file or into database.
Persistence - File#
It has 3 strategies to save data if it chooses to persistence as file format. In currently version of MultiRunnable, it has 3 strategies:
One Thread One File
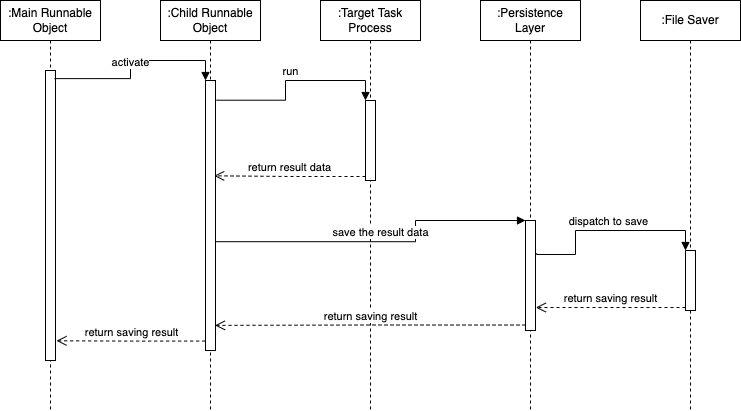
Every runnable object would save data as file.
Procedure is:
Main runnable object would initial and activate multiple child runnable objects.
Child runnable objects run target task.
In the target task, it would save data which be needed as file via persistence layer (FAO).
Sequence Diagram with One Thread One File of File:
All Threads One File
Every runnable objects would return the result data back to main runnable object, and main runnable object would save all the result data as target file format.
Procedure is:
Main runnable object would initial and activate multiple child runnable objects.
Child runnable objects run target task.
In the target task, it would return the result data back to outside (main runnable object).
Finally, it would save data which be needed as file via persistence layer (FAO) in main runnable object.
Sequence Diagram with All Threads One File of File:

One Thread One File and Compress All
Every runnable object would save data as target file format, it does the same thing as strategy One Thread One File. But main runnable object would compress all the files finally with this strategy.
Procedure is:
Main runnable object would initial and activate multiple child runnable objects.
Child runnable objects run target task.
In the target task, it would return a NamedTuple object which format is: key is file name (file path) and value is data streaming object.
Main runnable object would save the data as target file format and compress all of them.
Sequence Diagram with One Thread One File and Compress All of File:

Persistence - Database#
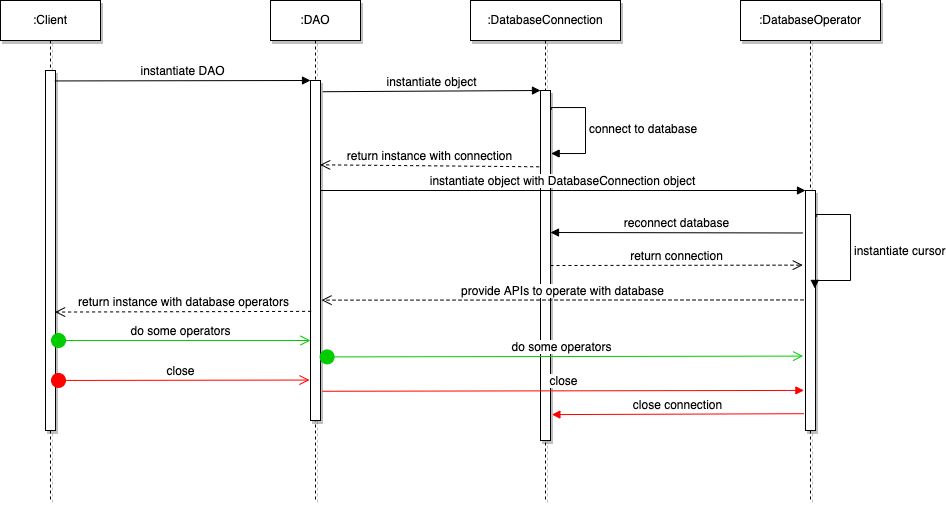
Persistence with database is the same as synchronous features modules, it has 2 sections are generating connection instance and operators with the database. For generating connection instance, it has 2 ways to implement: BaseSingleConnection or BaseConnectionPool. And its working flows are slightly difference with different ways.
Running Procedure:
Single one connection:
Connect and instantiate the database connection instance.
Initial database cursor instance via connection instance.
Do some operators by cursor instance.
Close the cursor instance.
Close the connection instance.
Connection Pool:
Check the key (class name) whether it exists in a global dictionary type value or not.
It’s a Singleton class, so it would check the whether instance exists or not before it instantiates it:
2-1. It returns the value (connection pool instance) of the key directly.
2-2. If it doesn’t have the key, it connect to database and initial a connection pool object. And it would save the pool instance into the global variable with pool name as key before it returns the pool instance.
Get one connection instance from the pool.
Initial database cursor instance via connection instance.
Do some operators by cursor instance.
Close the cursor instance.
Connection be release back to the pool instance.
Sequence diagram of Persistence-Database:
Retry Mechanism#
MultiRunnable has its own retry mechanism multirunnable.api.decorator.retry. It could do some processes of a target function.
Procedure is:
Run the initialization process (it doesn’t return anything).
Run the target function.
It has a try-catch on target function:
3-1. If it occurs exception, it would run the error-handling with the exception.
3-2. If it run finely without any issue, it would run the done-handling with the result data and set a running successfully flag.
4. No matter whether it occurs exception or not, it musts to run the final-handling finally. 5.Check the running successfully flag:
5-1. If it’s True, the task has done and return result data.
5-1. If it’s False, it would rerun the task function. It would occur timeout if it exceeds the retry times.
Here’s the activity diagram of Retry Mechanism:
